外观
YoloV8-训练与测试
制作数据集
Labelme 数据集
数据集选用我以前自己标注的数据集。点击下载
类别如下:
['c17', 'c5', 'helicopter', 'c130', 'f16', 'b2',
'other', 'b52', 'kc10', 'command', 'f15', 'kc135', 'a10',
'b1', 'aew', 'f22', 'p3', 'p8', 'f35', 'f18', 'v22', 'f4',
'globalhawk', 'u2', 'su-27', 'il-38', 'tu-134', 'su-33',
'an-70', 'su-24', 'tu-22', 'il-76']格式转换
将 Lableme 数据集转为 yolov8 格式的数据集,转换代码如下:
python
import os
import shutil
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwd
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def change_2_yolo5(files, txt_Name):
imag_name=[]
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
# image_path = labelme_path + json_file['imagePath']
imag_name.append(json_file_+'.jpg')
height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"].lower()
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# print(json_filename, xmin, ymin, xmax, ymax, cls_id)
return imag_name
def image_txt_copy(files,scr_path,dst_img_path,dst_txt_path):
"""
:param files: 图片名字组成的list
:param scr_path: 图片的路径
:param dst_img_path: 图片复制到的路径
:param dst_txt_path: 图片对应的txt复制到的路径
:return:
"""
for file in files:
img_path=scr_path+file
print(file)
shutil.copy(img_path, dst_img_path+file)
scr_txt_path=scr_path+file.split('.')[0]+'.txt'
shutil.copy(scr_txt_path, dst_txt_path + file.split('.')[0]+'.txt')
if __name__ == '__main__':
classes = ['c17', 'c5', 'helicopter', 'c130', 'f16', 'b2',
'other', 'b52', 'kc10', 'command', 'f15', 'kc135', 'a10',
'b1', 'aew', 'f22', 'p3', 'p8', 'f35', 'f18', 'v22', 'f4',
'globalhawk', 'u2', 'su-27', 'il-38', 'tu-134', 'su-33',
'an-70', 'su-24', 'tu-22', 'il-76']
# 1.标签路径
labelme_path = "USA-Labelme/"
isUseTest = True # 是否创建test集
# 3.获取待处理文件
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
for i in files:
print(i)
trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
# split
train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55)
train_name_list=change_2_yolo5(train_files, "train")
print(train_name_list)
val_name_list=change_2_yolo5(val_files, "val")
test_name_list=change_2_yolo5(test_files, "test")
#创建数据集文件夹。
file_List = ["train", "val", "test"]
for file in file_List:
if not os.path.exists('./VOC/images/%s' % file):
os.makedirs('./VOC/images/%s' % file)
if not os.path.exists('./VOC/labels/%s' % file):
os.makedirs('./VOC/labels/%s' % file)
image_txt_copy(train_name_list,labelme_path,'./VOC/images/train/','./VOC/labels/train/')
image_txt_copy(val_name_list, labelme_path, './VOC/images/val/', './VOC/labels/val/')
image_txt_copy(test_name_list, labelme_path, './VOC/images/test/', './VOC/labels/test/')运行完成后就得到了 yolov8 格式的数据集。 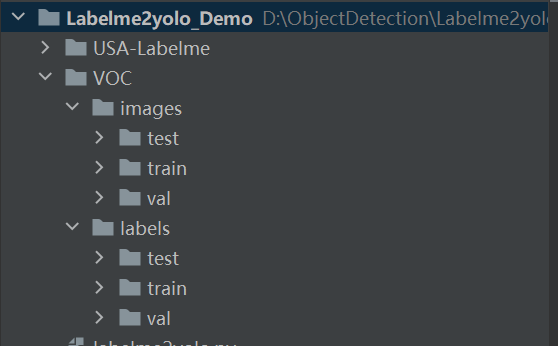
本地调试
在官网上下载 YoloV8,GitHub 链接: GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite 或者直接执行命令pip install ultralytics,如果你打算修改模型,或者二次创新,不建议使用安装命令安装。
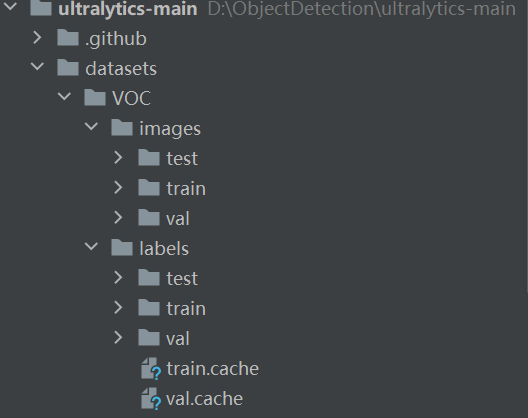
下载到本地后解压,将生成的 yolo 数据集放到 datasets(需要创建 datasets 文件夹)文件夹下面,如下图:
安装必要的库文件,安装命令:
pip install opencv-python
pip install numpy==1.23.5
pip install pyyaml
pip install tqdm
pip install matplotlib上面这些安装命令,缺哪些就安装哪些,注意 numpy 的版本,如果是 2.0 以上版本一定要把版本降下来。
然后在根目录新建 VOC.yaml 文件,如下图:
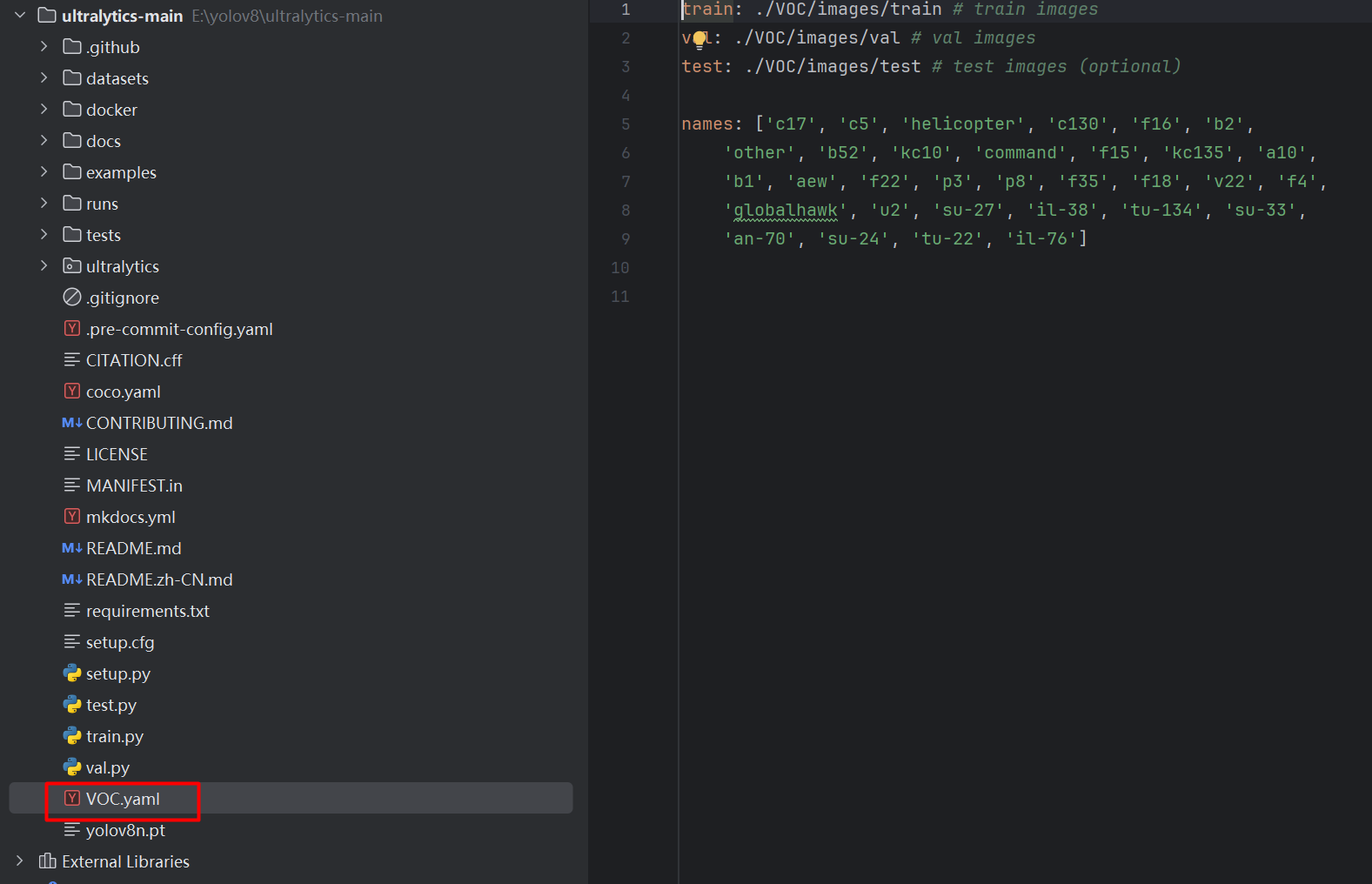
添加内容:
python
train: ./VOC/images/train # train images
val: ./VOC/images/val # val images
test: ./VOC/images/test # test images (optional)
names: ['c17', 'c5', 'helicopter', 'c130', 'f16', 'b2',
'other', 'b52', 'kc10', 'command', 'f15', 'kc135', 'a10',
'b1', 'aew', 'f22', 'p3', 'p8', 'f35', 'f18', 'v22', 'f4',
'globalhawk', 'u2', 'su-27', 'il-38', 'tu-134', 'su-33',
'an-70', 'su-24', 'tu-22', 'il-76']然后新建 train.py,如下图:
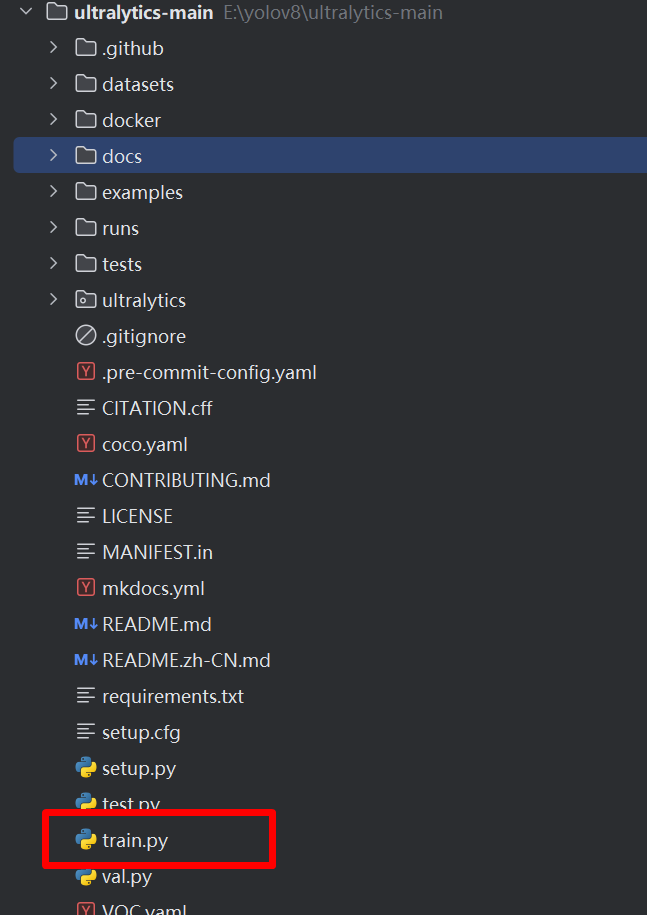
在 train.py 添加代码:
python
from ultralytics import YOLO
if __name__ == '__main__':
# 加载模型
model = YOLO("ultralytics/cfg/models/v8/yolov8l.yaml") # 从头开始构建新模型
print(model.model)
# Use the model
results = model.train(data="VOC.yaml", epochs=100, device='0', batch=16,workers=0) # 训练模型然后就可以看是训练了,点击 run 开始运行 train.py。
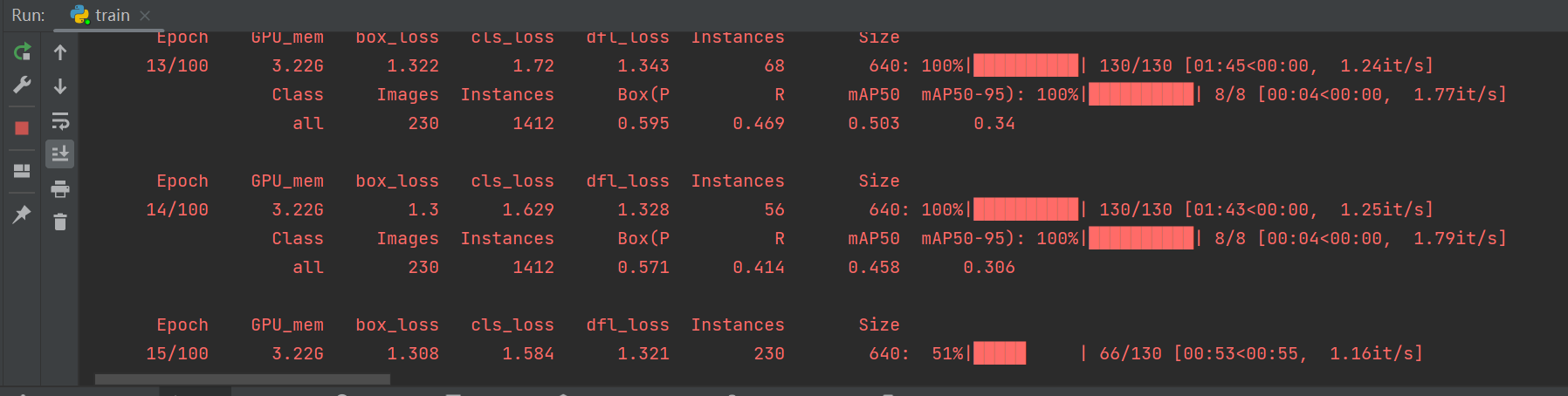
基于丹摩智算的训练
创建账号,登录官网后,就可以看到主页面了。 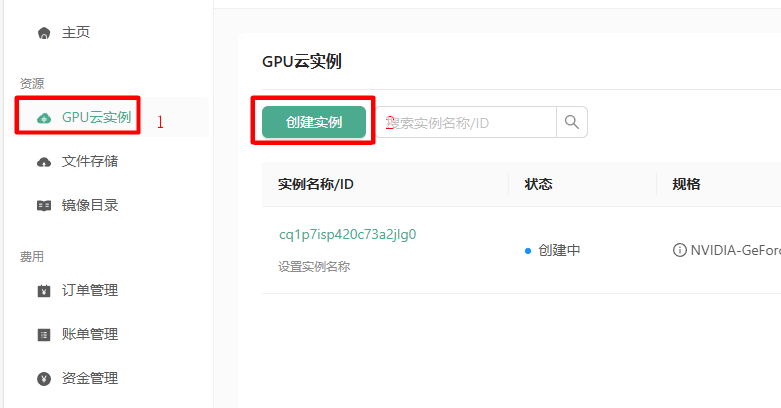 点击 GPU 云实例,然后再点击创建实例,进入创建实例的页面。
点击 GPU 云实例,然后再点击创建实例,进入创建实例的页面。
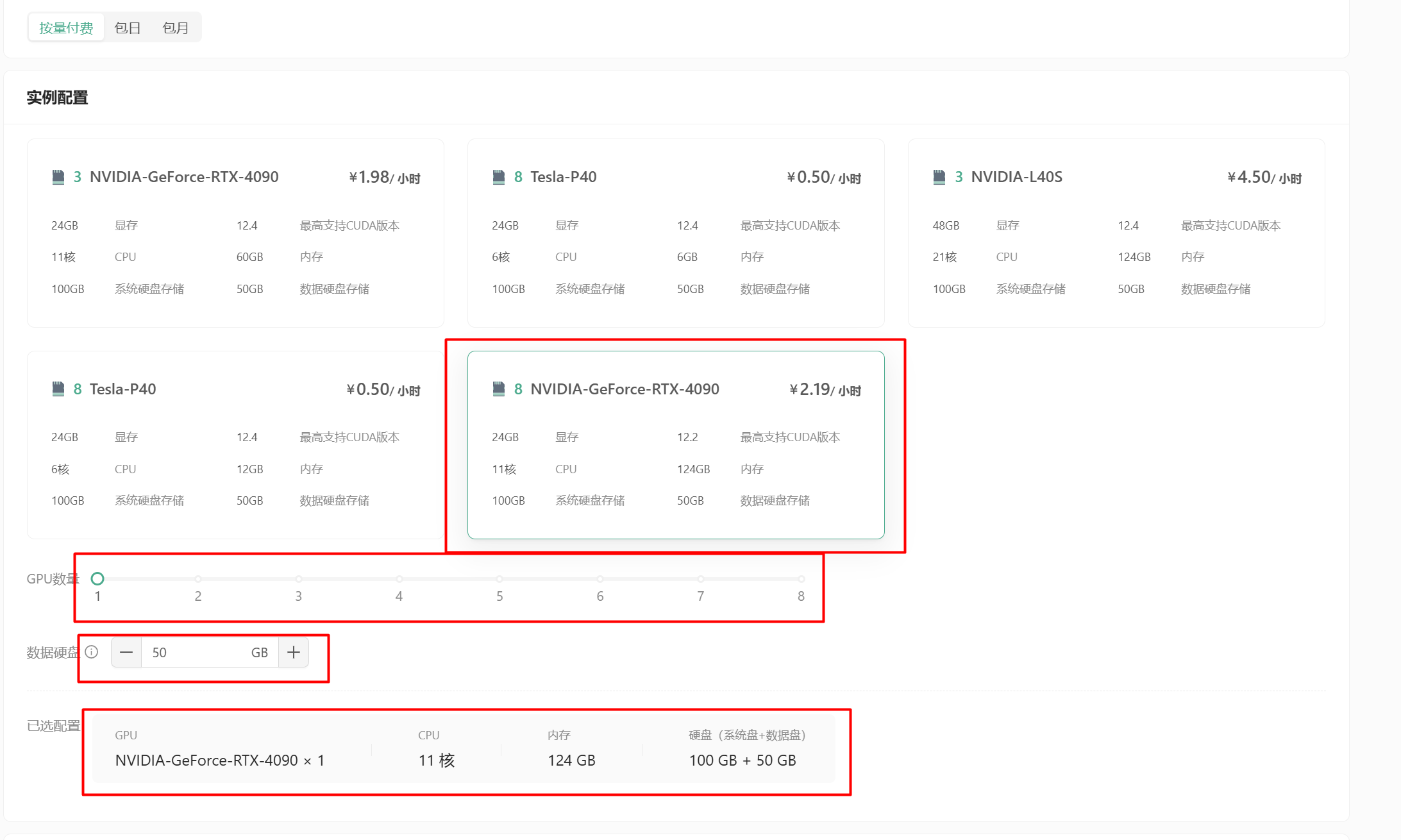
付费类型:可以选择按量付费,也可以选择包日,包月等。根据自己的需求选择。 实例配置:可以选择 GPU 的数量,CPU 的核数等信息来筛选列表的中配置。
选择具体的配置后,配置合适容量的数据盘。
在已选配置栏中,可以看到目前的详细配置信息。
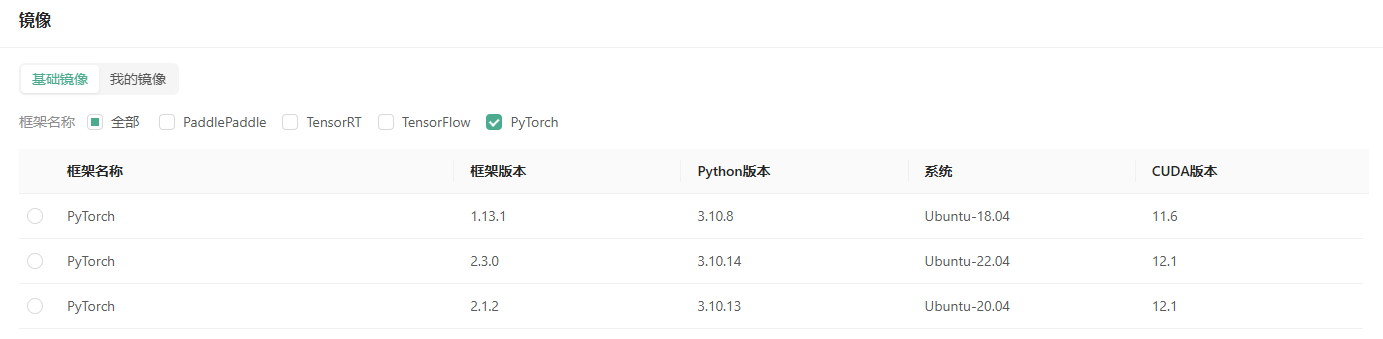 接下来选择镜像,目前主流平台的框架都是支持的,选择 Pytorch,就可以看到 Pytorch 的镜像信息。
接下来选择镜像,目前主流平台的框架都是支持的,选择 Pytorch,就可以看到 Pytorch 的镜像信息。
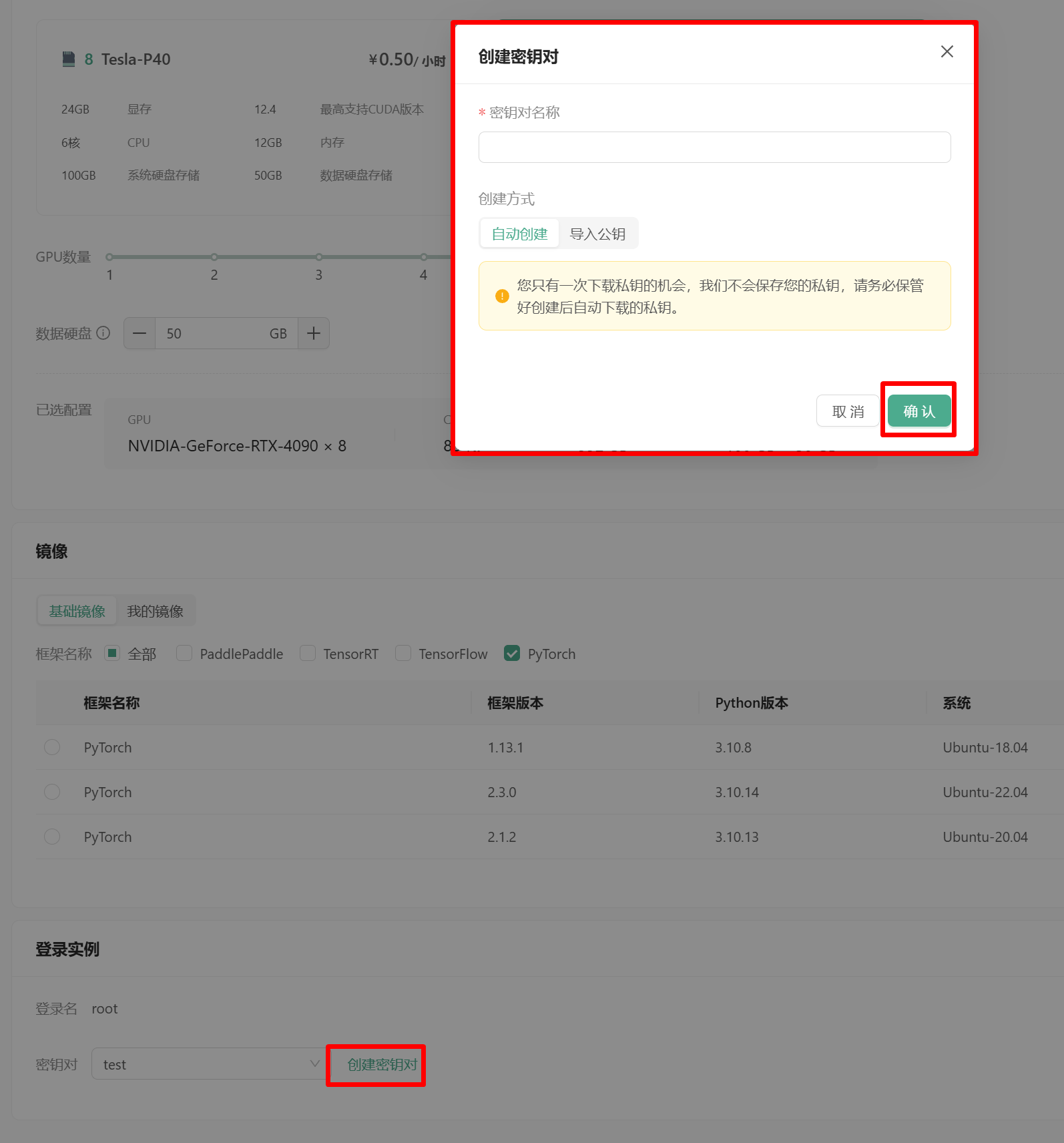 点击创建密钥对,弹出创建密钥的窗口,创建密钥或者导入公钥!
点击创建密钥对,弹出创建密钥的窗口,创建密钥或者导入公钥!  点击立即创建就可以创建实例了。
点击立即创建就可以创建实例了。

我创建了一个 P40 的实例,因为 4090 被抢没了!等待一会就可以了!  创建好后,点击 JupyterLab 进入控制台。
创建好后,点击 JupyterLab 进入控制台。  将我们刚才创建的工程压缩成 zip 的压缩包,等待上传。
将我们刚才创建的工程压缩成 zip 的压缩包,等待上传。 
 点击,文件夹样子的标签,进入根目录,然后点击
点击,文件夹样子的标签,进入根目录,然后点击↑,进入上传文件的页面。
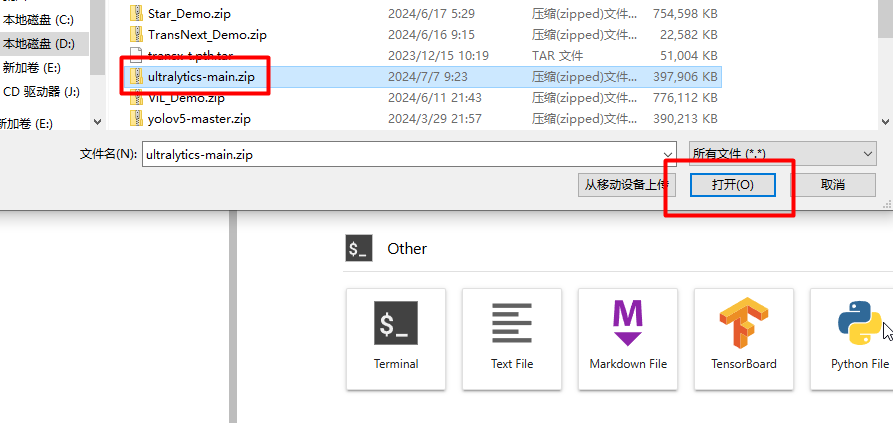 选择文件,点击打开。
选择文件,点击打开。 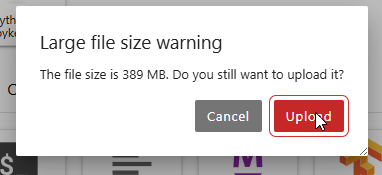
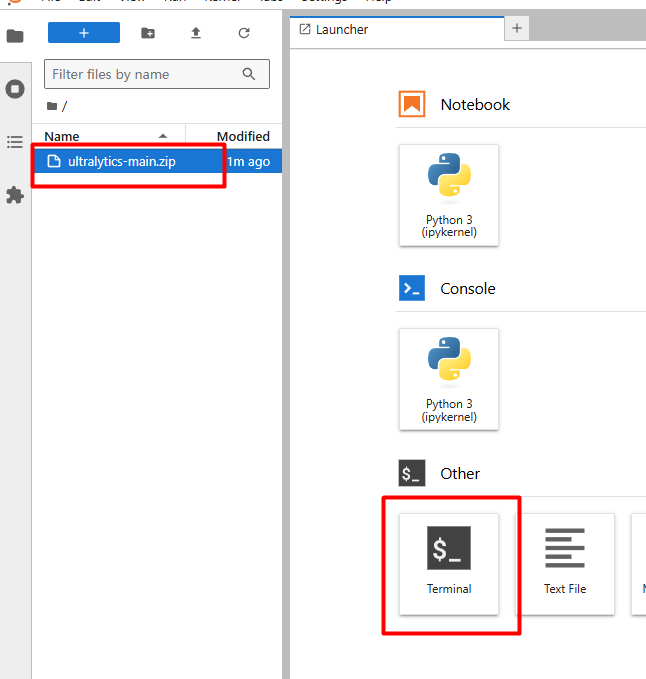 上传完成后,点击 Terminal,就可以进入我们熟悉的命令行界面。
上传完成后,点击 Terminal,就可以进入我们熟悉的命令行界面。 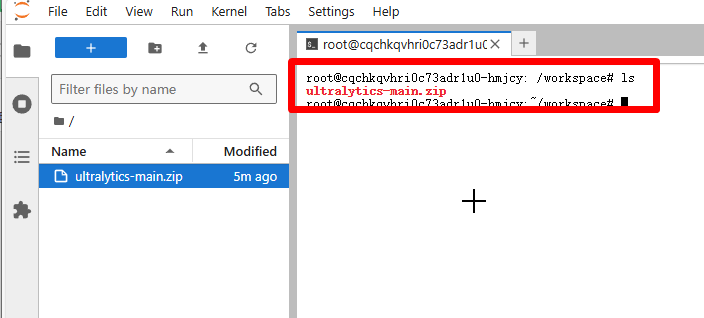 输入 ls,就可以看到我们刚才上传的压缩包!
输入 ls,就可以看到我们刚才上传的压缩包!
然后,输入:
unzip ultralytics-main.zip解压文件,如下图:
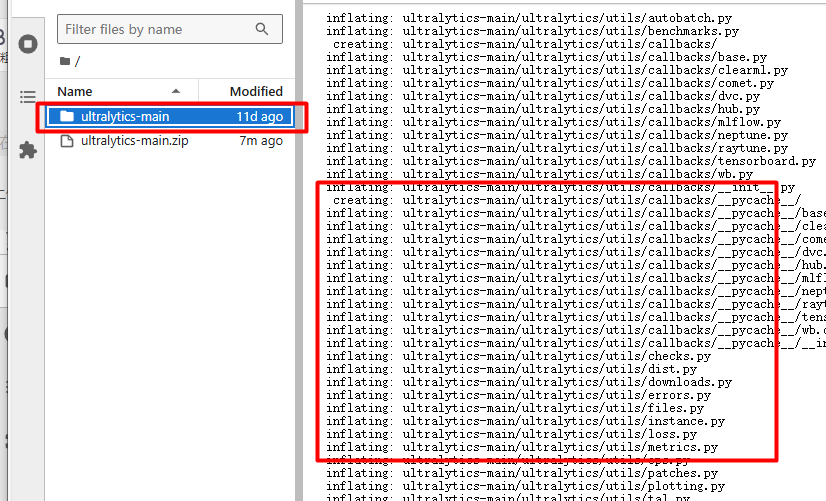
解压后就可以在左侧的目录中看到解压后的文件夹。点击进入。
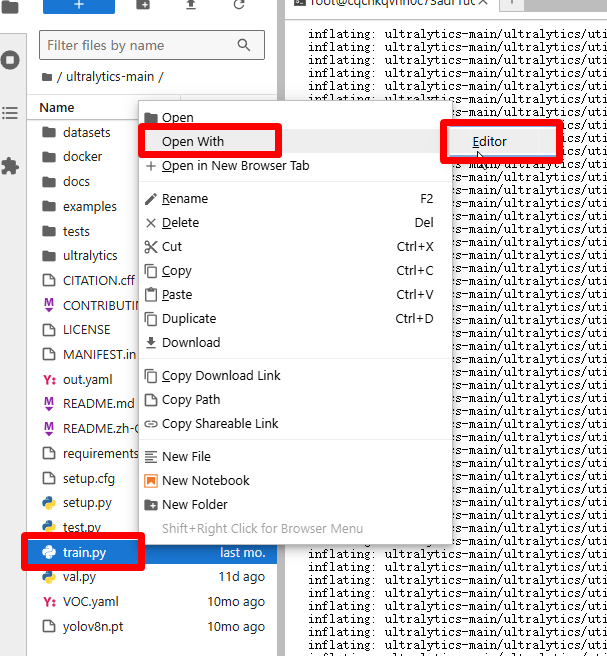 点击 train.py,Open With→Editor。
点击 train.py,Open With→Editor。
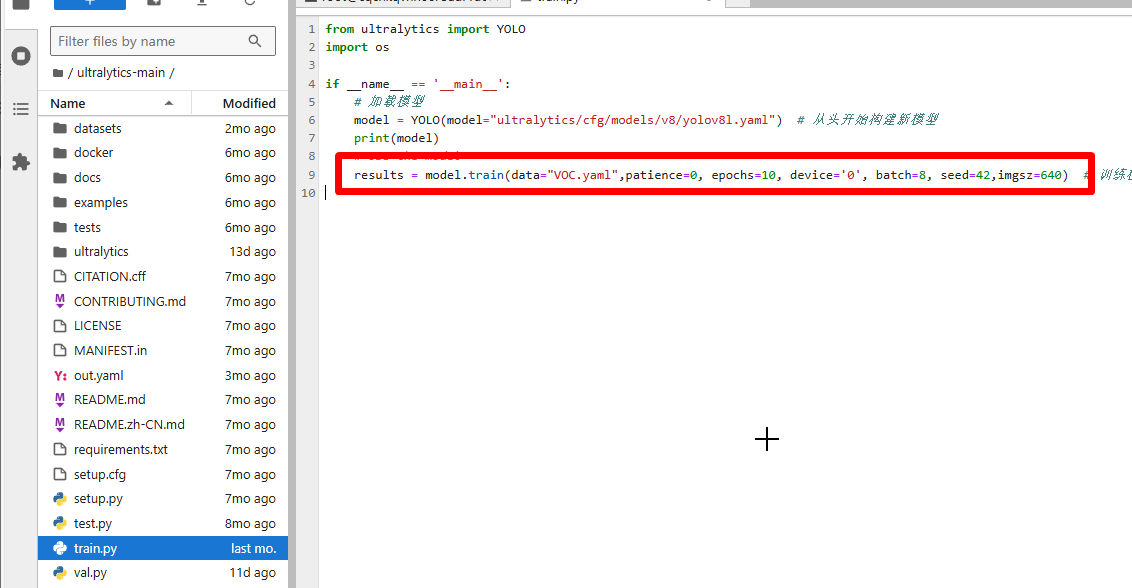 打开 train.py 后就可以修改 train.py 里面的参数了。
打开 train.py 后就可以修改 train.py 里面的参数了。
安装 YoloV8 运行所需要的库:
pip install opencv-python 如果遇到
如果遇到ImportError: libGL.so.1: cannot open shared object file: No such file or direc,这样的错误,需要安装:
python
pip install opencv-python-headlesspython
pip install pyyaml
pip install tqdm
pip install matplotlib
pip install pandas如果遇到有些文件下载不下来,可以尝试设置源,命令:
python
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 然后,执行命令,
然后,执行命令,python train.py就可以运行了.
测试
test.py 代码如下:
python
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
# model = YOLO('yolov8m.pt') # load an official model
model = YOLO('runs/detect/train/weights/best.pt') # load a custom model
results = model.predict(source="ultralytics/assets", device='0') # predict on an image
print(results)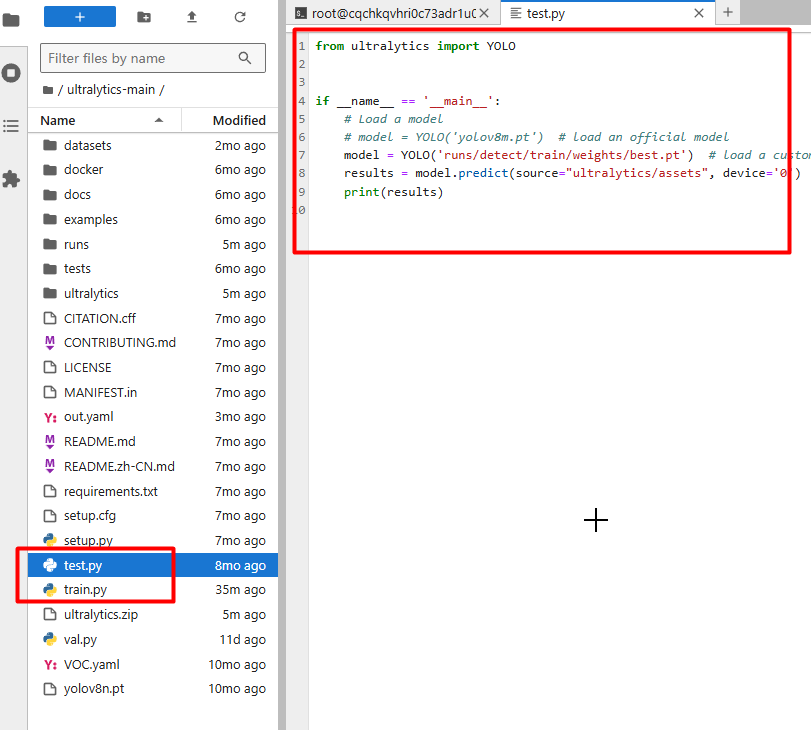 执行测试,就可以测试图片了。
执行测试,就可以测试图片了。