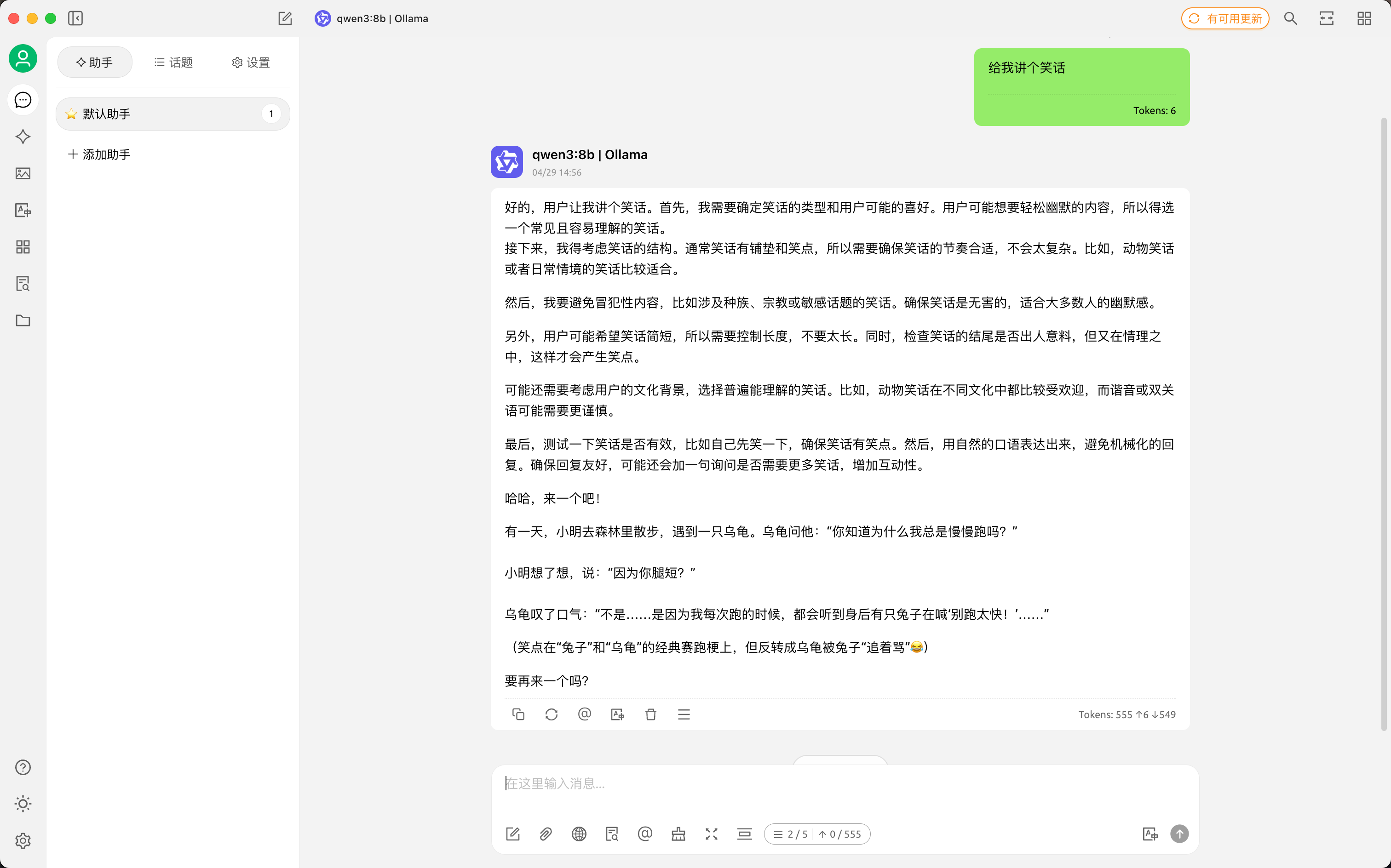
外观
Qwen3 部署与使用
模型简介
Qwen3是Qwen系列中最新一代的大型语言模型,提供了一套全面的密集和混合专家(MoE)模型。基于广泛的培训,Qwen3在推理、遵循指令、代理功能和多语言支持方面取得了突破性的进步,具有以下主要特点:
- 独特支持单一模型内思维模式(用于复杂逻辑推理、数学和编码)和非思维模式(用于高效、通用对话)之间的无缝切换,确保跨各种场景的最佳性能。
- 其推理能力显着增强,超过了以前的QwQ(在思维模式下)和Qwen2.5在数学、代码生成和常识逻辑推理方面指导模型(在非思维模式下)。
- 卓越的人类偏好对齐,擅长创意写作、角色扮演、多轮对话和指导跟随,以提供更自然、更具吸引力和身临其境的对话体验。
- 代理功能方面的专业知识,能够以思考和非思考模式与外部工具进行精确集成,并在基于代理的复杂任务中实现开源模型中的领先性能。
- 支持100多种语言和方言,具有强大的多语言教学能力,遵循和翻译。
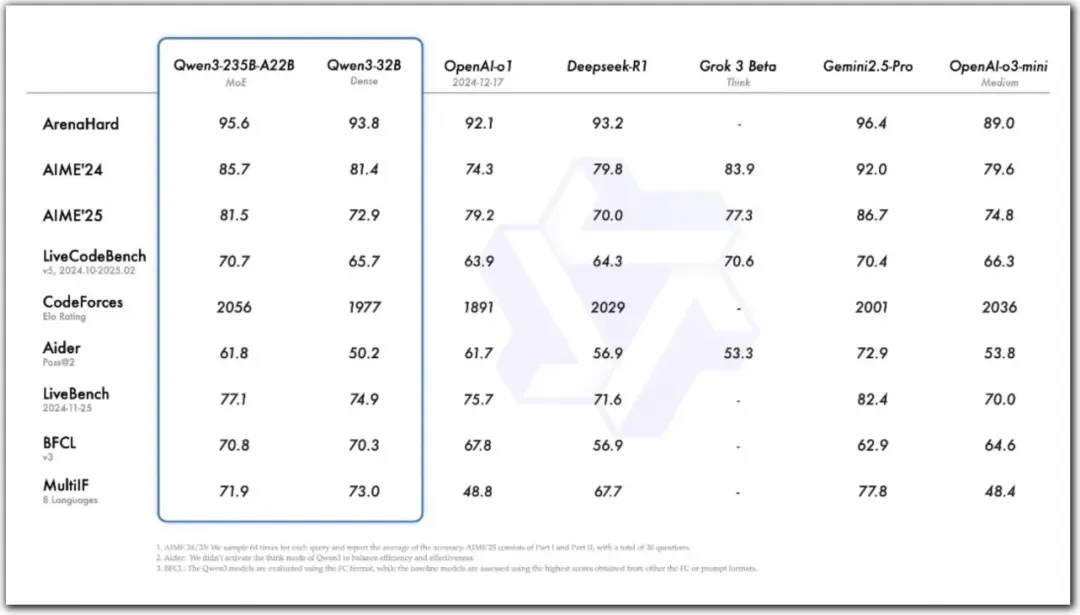

推荐配置
| 模型 | Ollama默认推荐配置 |
|---|---|
| Qwen3-0.6B | 3090 * 1 |
| Qwen3-1.7B | 3090 * 1 |
| Qwen3-4B | 3090 * 1 |
| Qwen3-8B | 4090 * 1 |
| Qwen3-14B | 4090 * 1 |
| Qwen3-30B | 4090 * 1 |
| Qwen3-32B | 4090 * 1 |
| Qwen3-235B | 4090 * 8 或 A800 * 3 |
部署教程
丹摩平台现已同步支持 Qwen 3 开箱即用镜像部署,进入控制台-GPU云实例,点击创建实例:
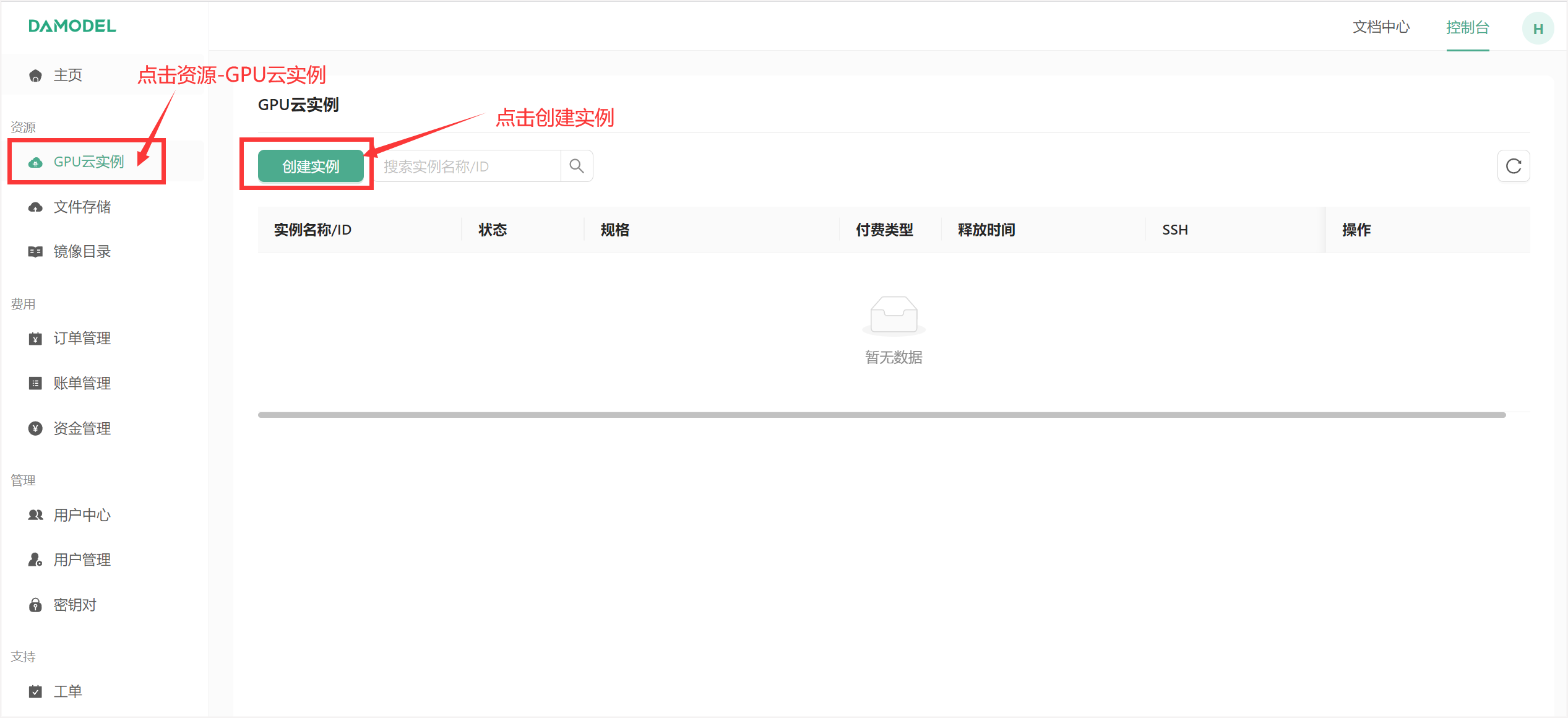
进入创建页面后,首先在实例配置中选择付费类型,一般短期需求可以选择按量付费或者包日,长期需求可以选择包月套餐;
其次选择GPU数量和需求的GPU型号,首次创建实例推荐选择:
- 按量付费
- GPU数量:1
- NVIDIA-GeForce-RTX-4090:该配置为124GB内存,24GB的显存
接下来配置数据硬盘的大小,每个实例默认附带了50GB的数据硬盘,使用默认大小即可。
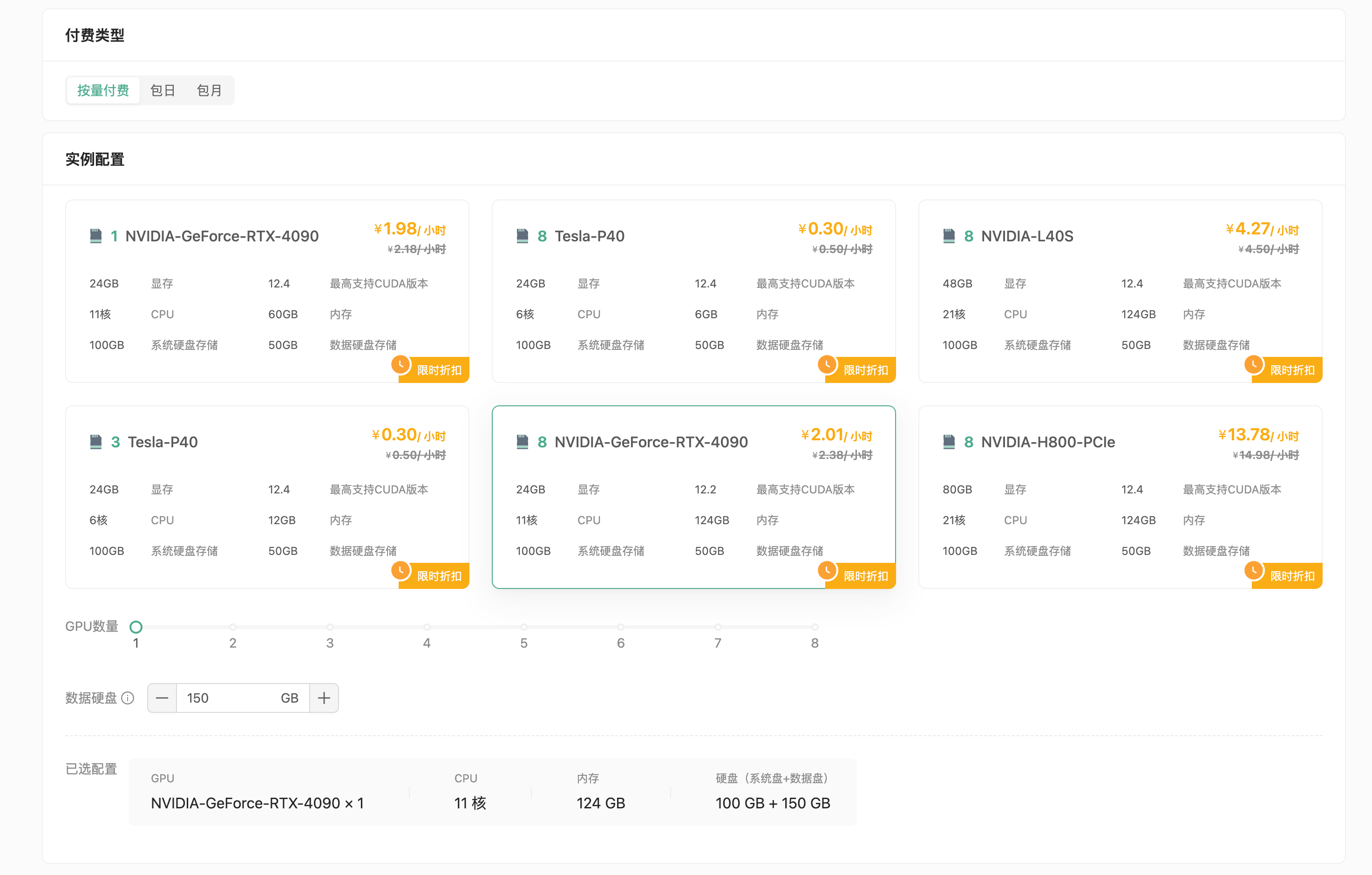
继续选择安装的镜像,请选择 Ollama 镜像,此镜像支持所有 Qwen 3 模型基于Ollama进行推理,请参考上文配置推荐依据您想使用的模型选择GPU配置。

网页使用
快速开始
实例状态进入「运行中」后,点击「实例服务—更多—Open-WebUI」,启动open-webui界面。

点击「开始使用」。

接着填入注册信息完成注册,首个注册的账号会成为超级管理员。

注册完成后即可体验。

常见问题
- 如果您需要与您的朋友共同使用open-webui,请您前往「管理员面板-设置-通用-允许新用户注册」并开启,默认用户角色按需设置。然后前往「管理员面板-设置-模型」设置模型可见性。
- 更多操作介绍请您参考open-webui官方文档:https://docs.openwebui.com/
客户端使用
实例状态进入「运行中」后,点击「实例服务—更多—Ollama」。

如果打开的网页显示:Ollama is running 表示服务可用,请您复制网页链接,如:http://cu***************0-11434.agent.damodel.com/。此链接为Ollama服务的API地址,接下来需要在客户端中配置。
下面依据两款热门本地LLM客户端工具演示配置方法,其他工具配置方法大体相同。
ChatBox
Chatbox AI是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
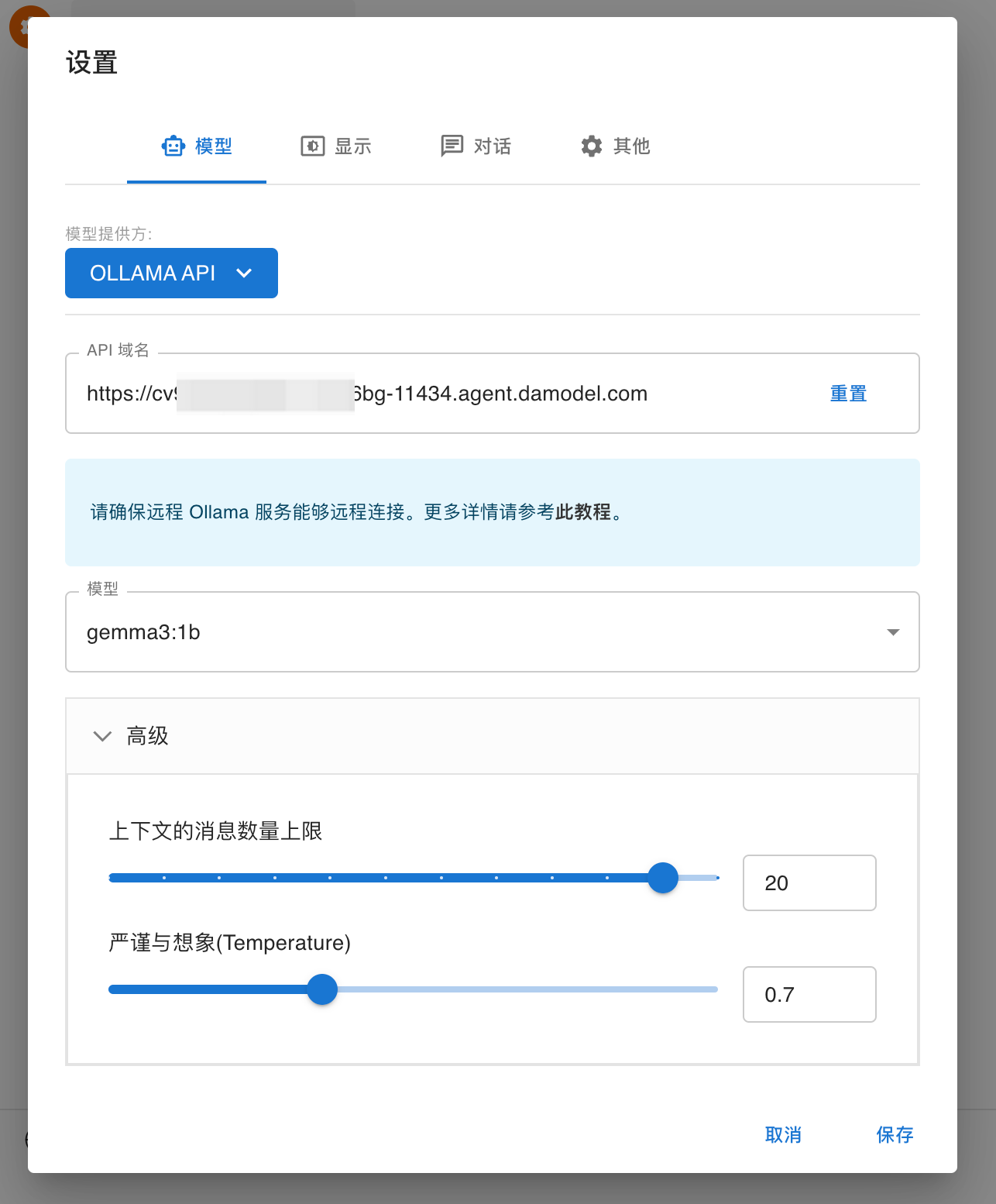
点击左下角「设置」

选择标签页「模型」:
- 「模型提供方」选择「OLLAMA API」
- 「API域名」填入刚刚复制的Ollama API地址(注意需填写https地址)
- 「模型」在API地址填入后会自动加载支持的模型,您依据您的实例配置自行选择
- 其余选项采用默认值即可
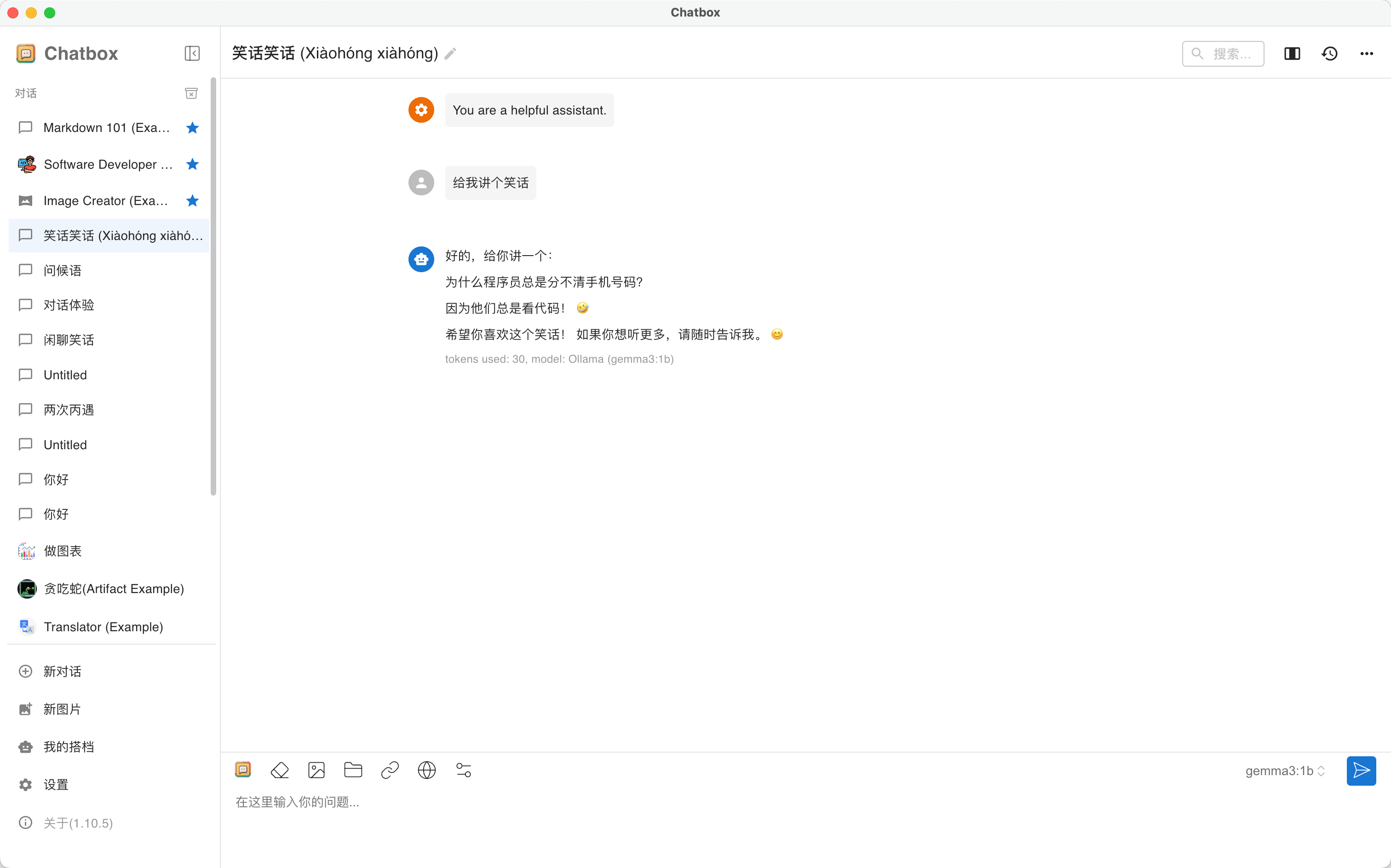
保存后即可使用模型推理,更多操作教程详见ChatBox帮助中心。
CherryStudio
CherryStudio支持多服务商集成的AI对话客户端,目前支持市面上绝大多数服务商的集成,并且支持多服务商的模型统一调度。
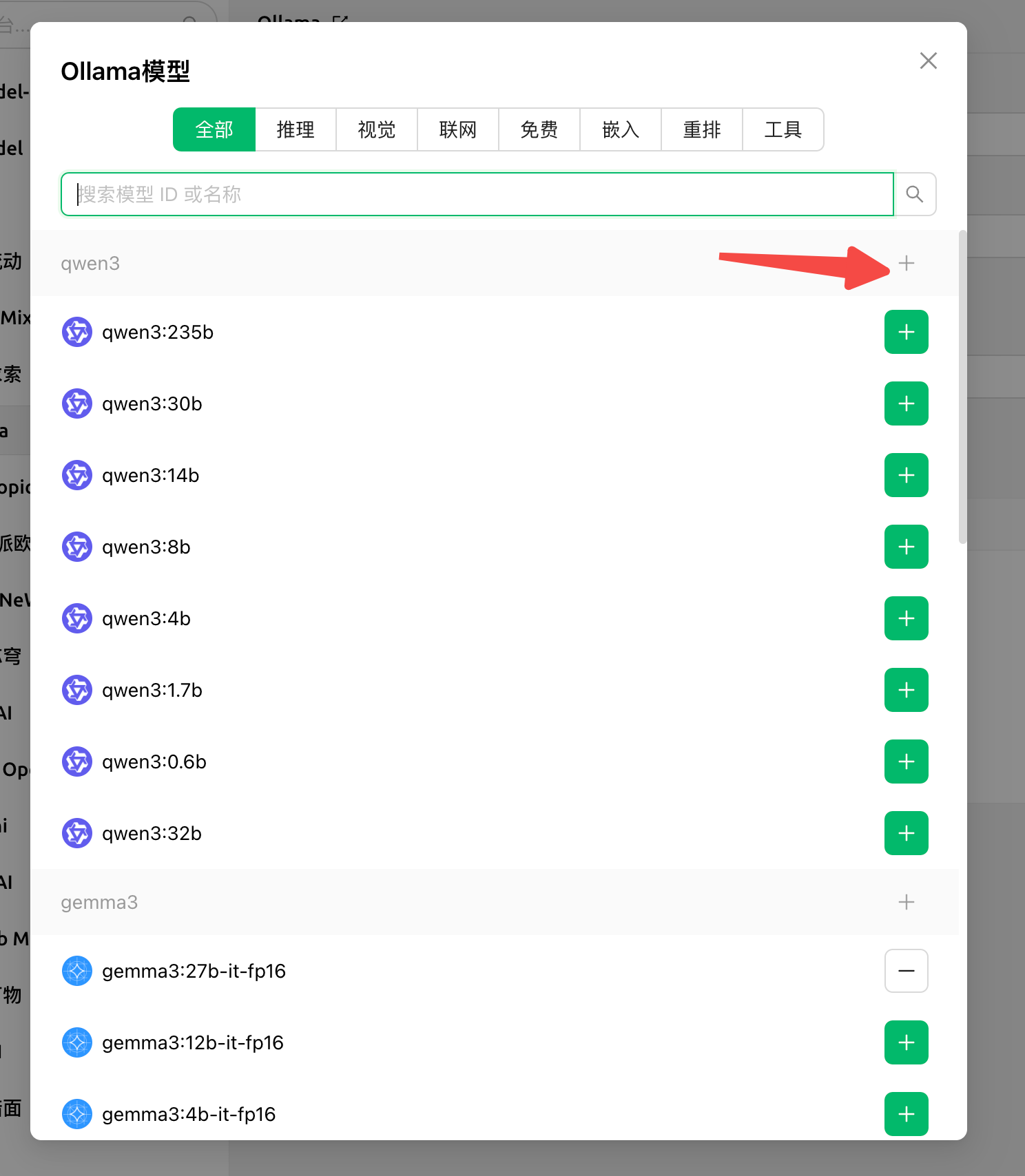
点击左下角「设置」

- 「Ollama」开启
- 「API地址」填入刚刚复制的Ollama API地址(注意需填写https地址)
- 「模型」点击管理,在API地址填入后会自动加载支持的模型,您依据您的实例配置自行选择
- 其余选项采用默认值即可

返回「对话」页面,点击上方「当前模型」按钮,选择刚刚配置的模型,即可开始对话体验。更多操作教程详见CherryStudio文档中心。