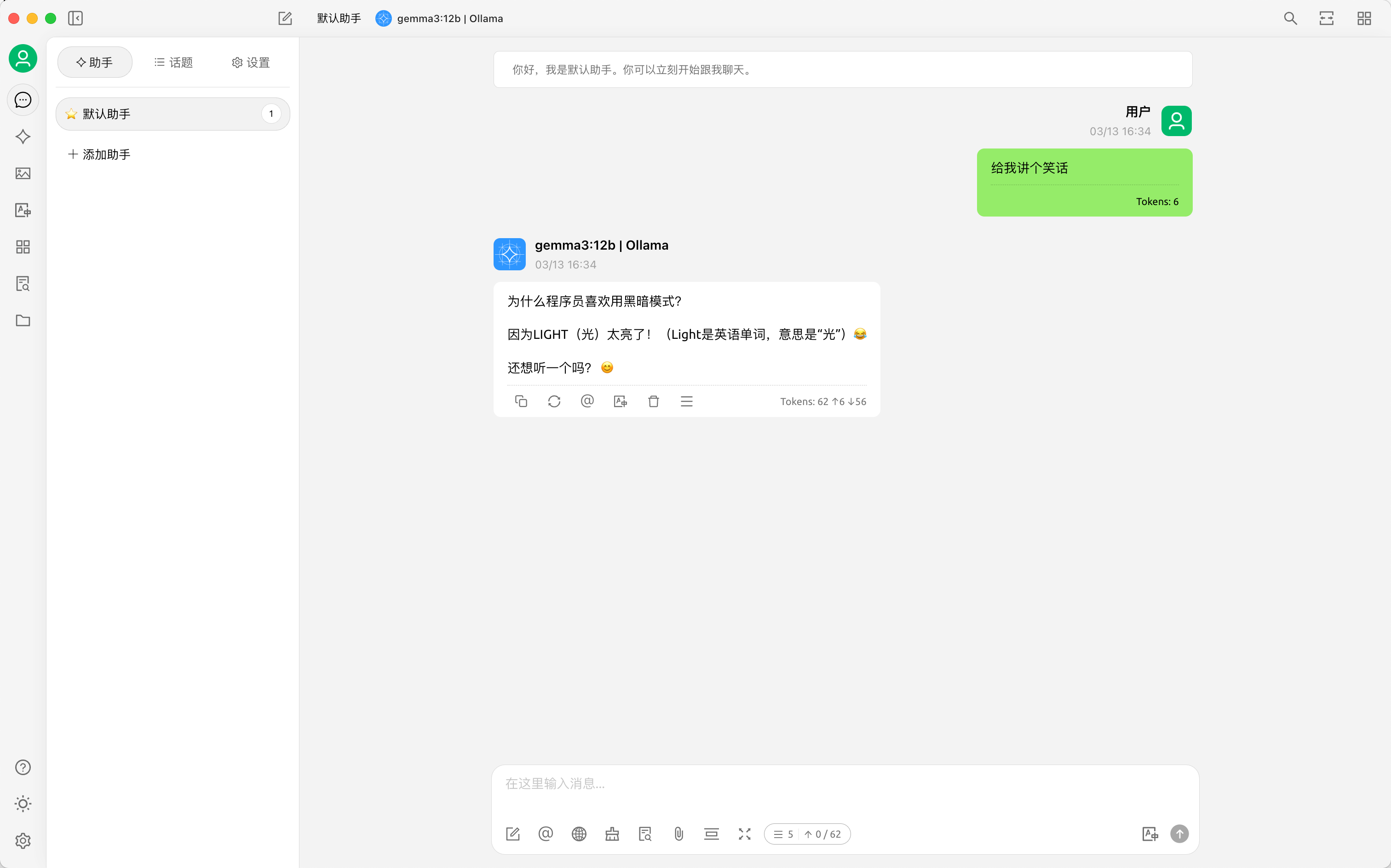
外观
Gemma 3 部署与使用
模型简介
近期,Google 发布了最新的 Gemma 3,Gemma 3 是一系列先进的轻量级开放模型,采用与 Gemini 2.0 模型相同的研究成果和技术构建而成。
- 处理复杂任务:借助 Gemma 3 的 128K 令牌上下文窗口,您的应用可以处理和理解大量信息,从而实现更复杂的 AI 功能;
- 立即进军全球市场:借助 Gemma 3 无与伦比的多语言功能,轻松跨语言沟通。开发面向全球受众群体的应用,支持 140 多种语言;
- 理解文字和图片:轻松构建可分析图片、文本和视频的应用,为互动式和智能应用开辟新的可能性。
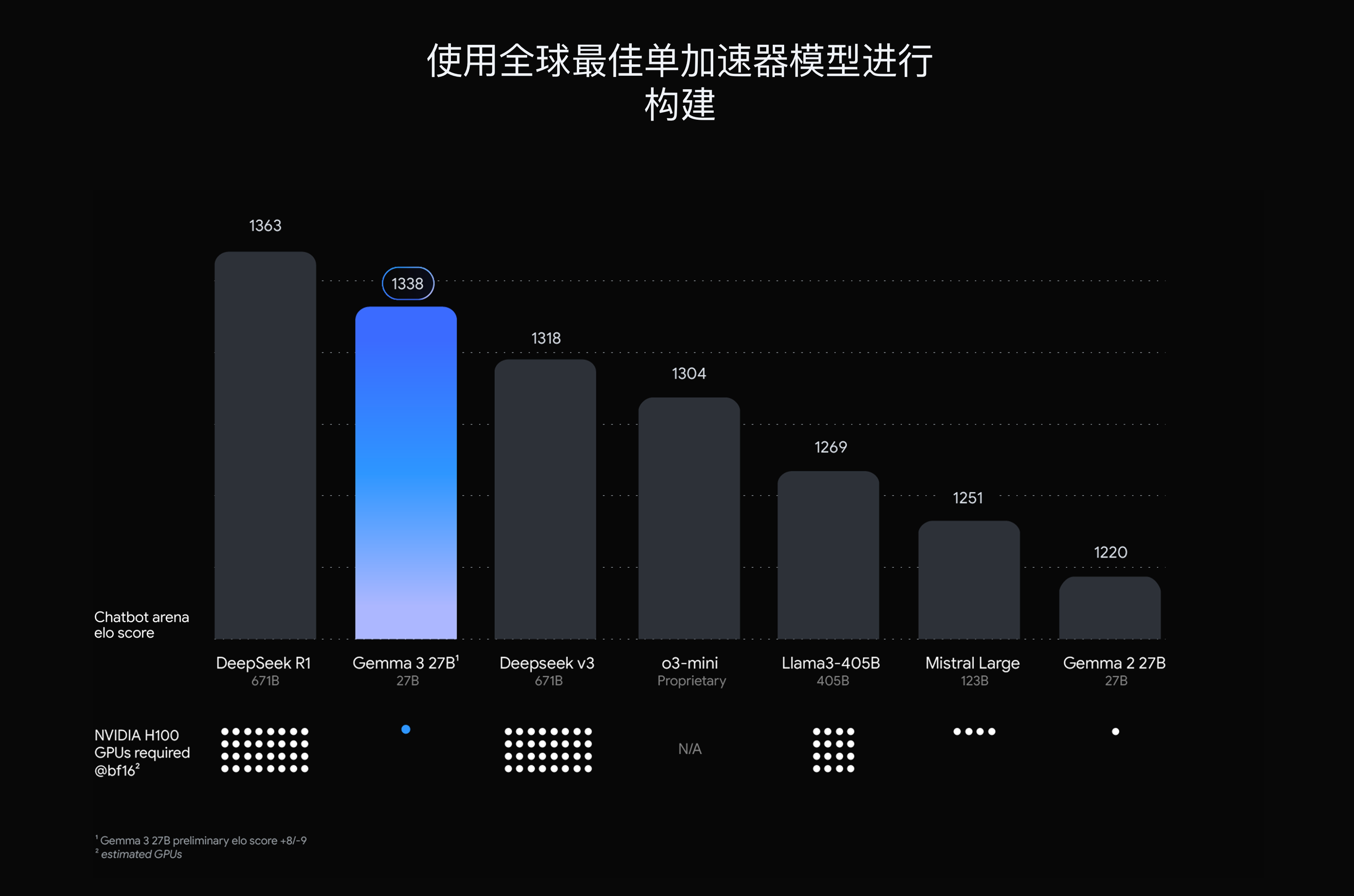
需关注
Gemma 3 不同参数量版本,支持的语言、上下文长度、输入类型各不相同,请您参考下表选择符合您需求的版本体验。
| 模型 | 推荐推理配置 | 上下文长度 | 语言支持 | 输入类型 |
|---|---|---|---|---|
| Gemma 3 1B | 默认:3090 * 1 fp16:3090 * 1 | 32k | 英语 | 文本 |
| Gemma 3 4B | 默认:3090 * 1 fp16:3090 * 1 | 128k | 140+多语言 | 文本/图片 |
| Gemma 3 12B | 默认:4090 * 1 fp16:4090 * 2 | 128k | 140+多语言 | 文本/图片 |
| Grmma 3 27B | 默认:4090 * 1 fp16:4090 * 3 | 128k | 140+多语言 | 文本/图片 |
部署教程
丹摩平台现已同步支持 Gemma 3 开箱即用镜像部署,进入控制台-GPU云实例,点击创建实例:
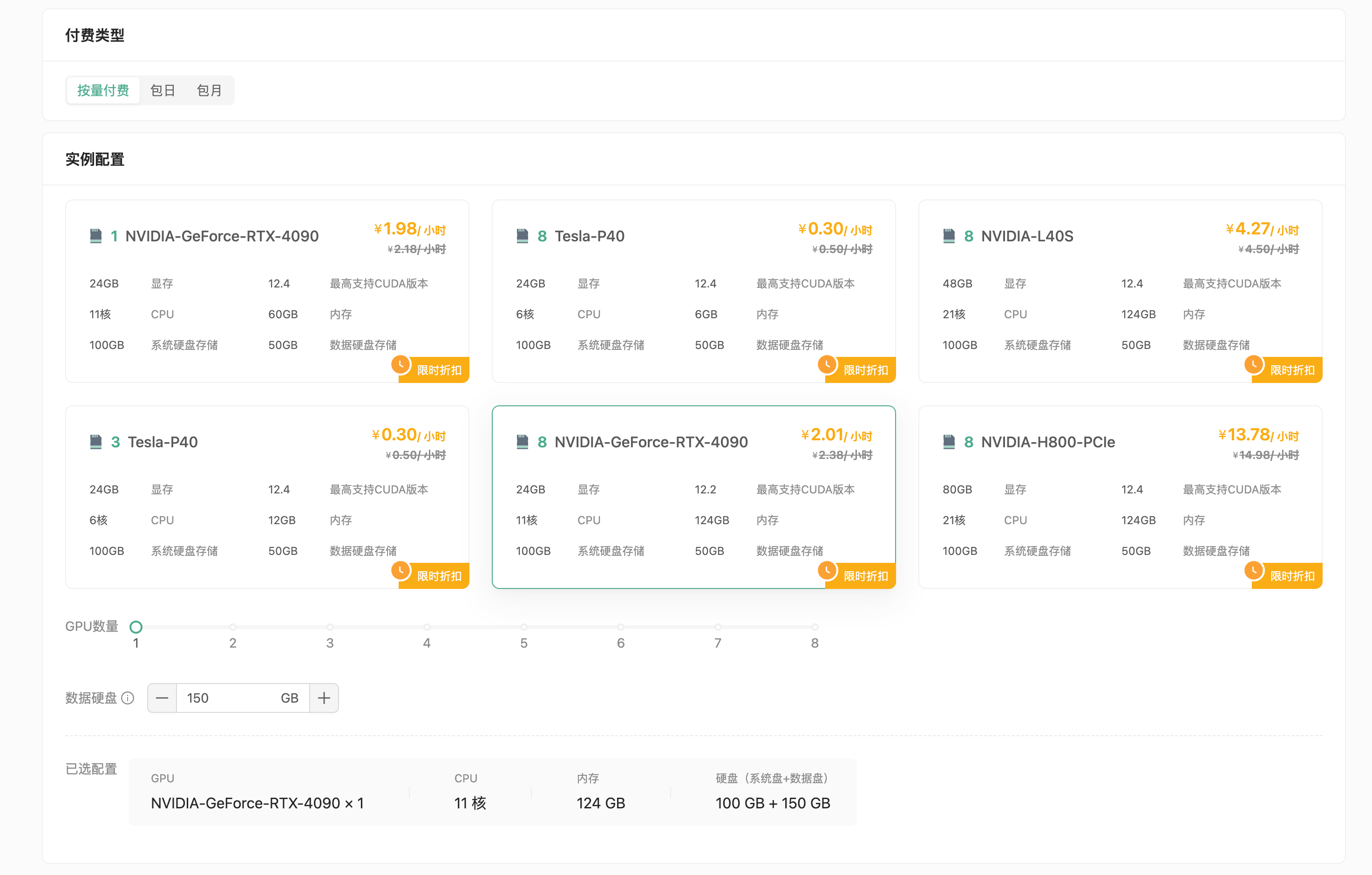
进入创建页面后,首先在实例配置中选择付费类型,一般短期需求可以选择按量付费或者包日,长期需求可以选择包月套餐;
其次选择GPU数量和需求的GPU型号,首次创建实例推荐选择:
- 按量付费
- GPU数量:1
- NVIDIA-GeForce-RTX-4090:该配置为124GB内存,24GB的显存
接下来配置数据硬盘的大小,每个实例默认附带了50GB的数据硬盘,使用默认大小即可。
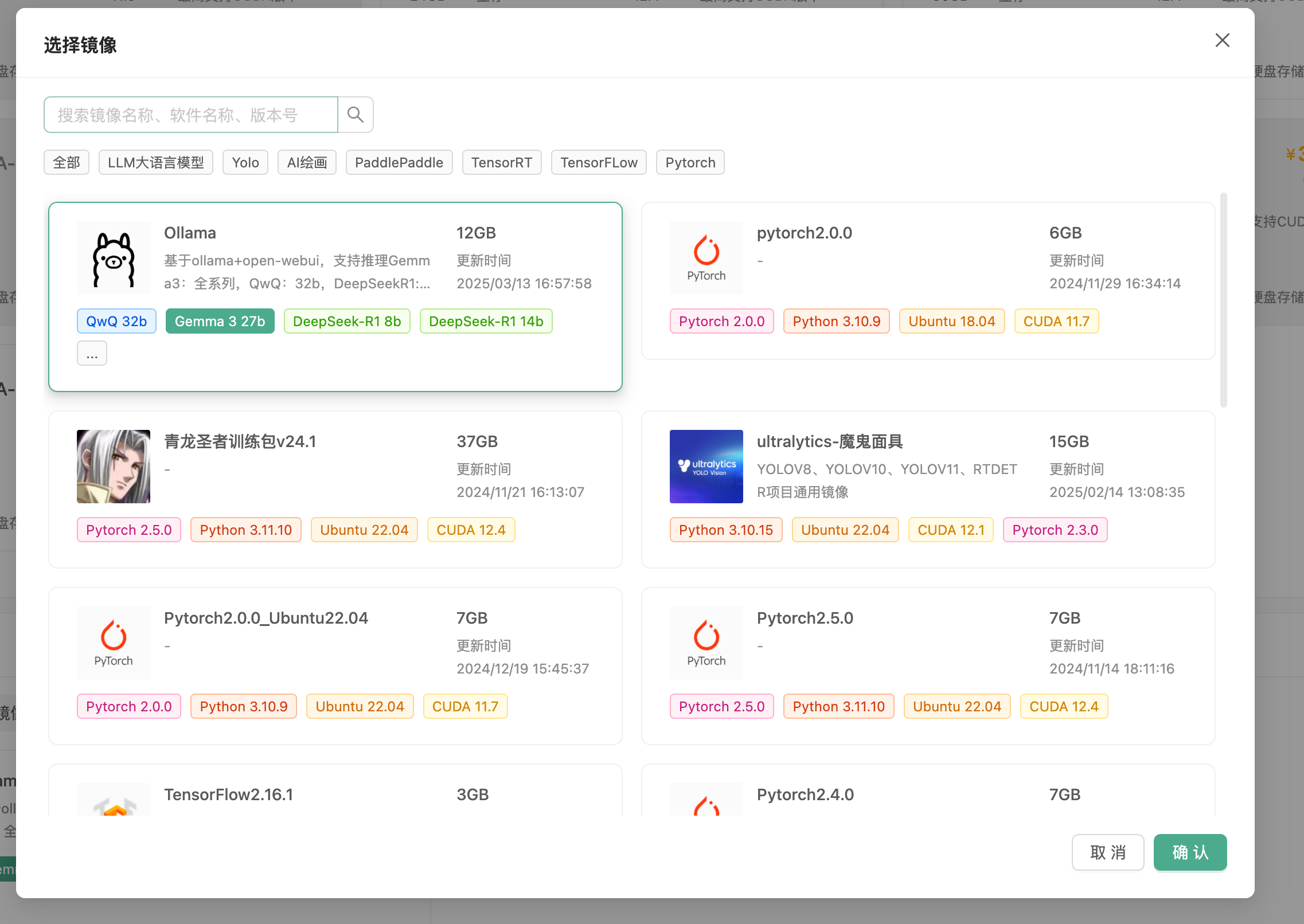
继续选择安装的镜像,请选择 Ollama 镜像,此镜像支持所有 Gemma 3 模型基于Ollama进行推理,请参考上文配置推荐依据您想使用的模型选择GPU配置。
网页使用
快速开始
实例状态进入「运行中」后,点击「实例服务—更多—Open-WebUI」,启动open-webui界面。

点击「开始使用」。

接着填入注册信息完成注册,首个注册的账号会成为超级管理员。

注册完成后即可体验。
常见问题
- 如果您需要与您的朋友共同使用open-webui,请您前往「管理员面板-设置-通用-允许新用户注册」并开启,默认用户角色按需设置。然后前往「管理员面板-设置-模型」设置模型可见性。
- 更多操作介绍请您参考open-webui官方文档:https://docs.openwebui.com/
客户端使用
实例状态进入「运行中」后,点击「实例服务—更多—Ollama」。

如果打开的网页显示:Ollama is running 表示服务可用,请您复制网页链接,如:http://cu***************0-11434.agent.damodel.com/。此链接为Ollama服务的API地址,接下来需要在客户端中配置。
下面依据两款热门本地LLM客户端工具演示配置方法,其他工具配置方法大体相同。
ChatBox
Chatbox AI是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
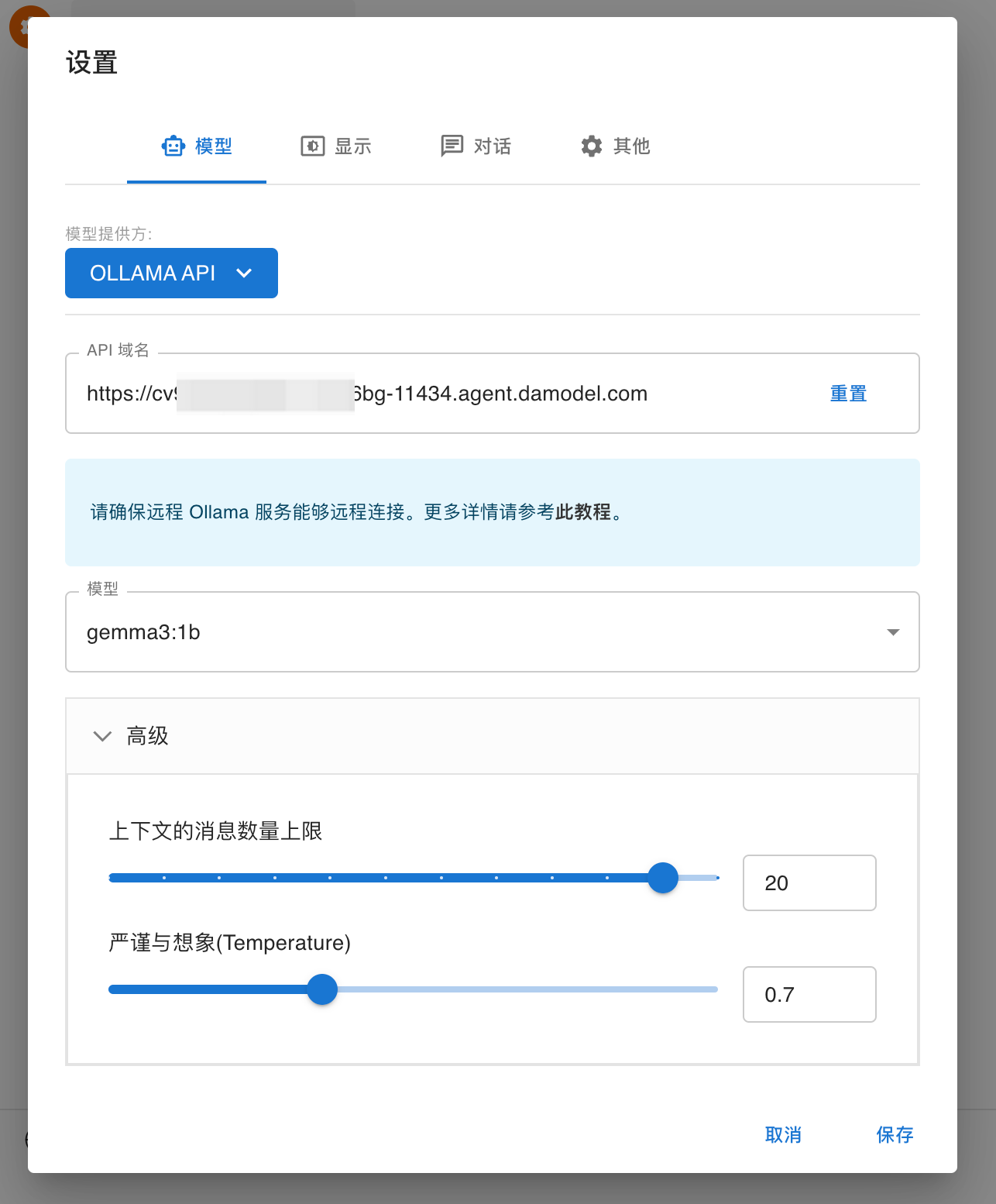
点击左下角「设置」

选择标签页「模型」:
- 「模型提供方」选择「OLLAMA API」
- 「API域名」填入刚刚复制的Ollama API地址(注意需填写https地址)
- 「模型」在API地址填入后会自动加载支持的模型,您依据您的实例配置自行选择
- 其余选项采用默认值即可
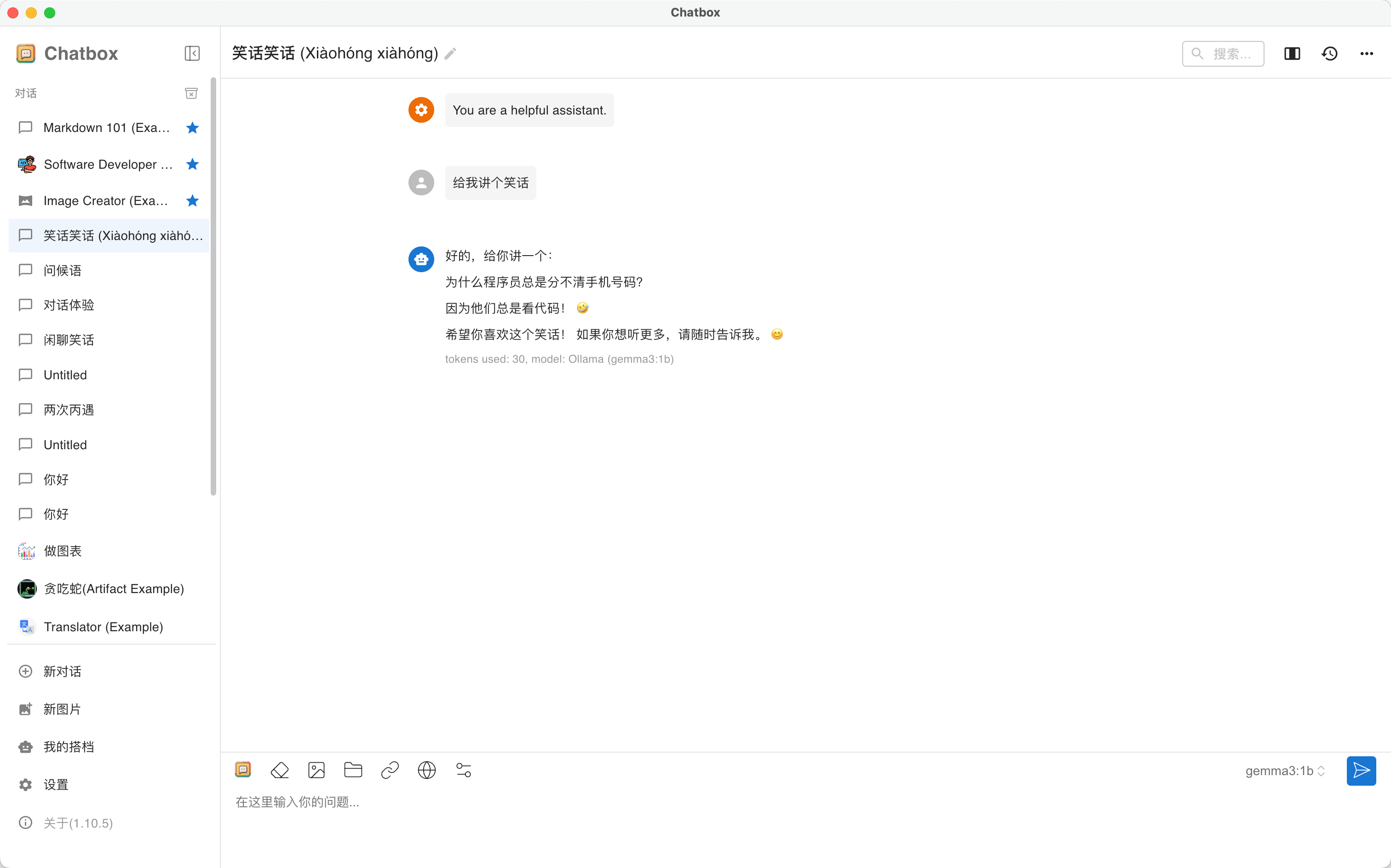
保存后即可使用模型推理,更多操作教程详见ChatBox帮助中心。
CherryStudio
CherryStudio支持多服务商集成的AI对话客户端,目前支持市面上绝大多数服务商的集成,并且支持多服务商的模型统一调度。
点击左下角「设置」

进入「模型服务-Ollama」:
- 「Ollama」开启
- 「API地址」填入刚刚复制的Ollama API地址(注意需填写https地址)
- 「模型」点击管理,在API地址填入后会自动加载支持的模型,您依据您的实例配置自行选择
- 其余选项采用默认值即可

返回「对话」页面,点击上方「当前模型」按钮,选择刚刚配置的模型,即可开始对话体验。更多操作教程详见CherryStudio文档中心。